Your Coronavirus Telemedicine Health App Might Be Overrated: How to Tell
Photo of the author’s glassboard.
Introduction
We would overstate our health app’s effectiveness by claiming it reduces the risk of new coronavirus infections by 16.9%—when in fact it will only reduce this risk by 3.1%.
But we can re-weight our real-world evidence results to provide more accurate risk-reduction estimates of either 2.3% or 2.2%.
To review from Part 1 of this two-part tutorial using synthetic data:
Our analysis goal will be to help public health authorities in our simulated world reduce SARS-CoV-2 (“coronavirus”) infections. We believe our digital health or telemedicine app can help prevent new infections; e.g., by promoting healthy lifestyle choices—particularly while social distancing and sheltering-in-place—that reduce the risk of coronavirus infection. But to do this, we’ll need an unbiased or statistically consistent (i.e., more unbiased with larger samples) estimate of the true effect of our would-be intervention.
Tutorial Goal: To understand how causal assumptions change our interpretation of predictions, moving them towards explanations. To understand why this is needed before we can quantify the impact of our tech solution.
What We’ll Learn: How to recognize the difference between a modeling association and a causal effect. How to conduct causal inference via the g-formula (Robins, 1986; Hernán and Robins, 2006) and propensity score weighting (Rosenbaum and Rubin, 1983; Hirano and Imbens, 2001; Lunceford and Davidian, 2004).
We will learn how a confounder biases our estimate of the would-be effect of a hypothetical health app intervention. The biases that emerge from our synthetic data are shown below.
| Part | Study Design | Confounder Adjustment | Empirical Bias | Estimated Risk Reduction |
|---|---|---|---|---|
| 1 | RWE (observational study) | not done | -0.138 | overstated |
| 2 | RCT (experimental study) | not done | -0.003 | consistently estimated |
| 2 | RWE (observational study) | g-formula | 0.008 | consistently estimated |
| 2 | RWE (observational study) | propensity score weighting | 0.010 | consistently estimated |
In Part 1, we investigated a synthetic real-world evidence (RWE) dataset inspired by a recent healthcare example involving racial disparities in COVID-19 cases (Garg et al, 2020; Aubrey, 2020). (Synthetic data are simulated—not real—data commonly created to teach or learn about an analytical tool.)
We learned how to recognize the difference between a statistical contrast (e.g., risk difference) and a causal effect. We also saw why it wasn’t enough, in general, to state the causal mechanisms (e.g., directed acyclic graph) and control for all confounders (assuming we observed all of them in our dataset) in our analysis—as is done in an explanatory or prediction model (Shmueli, 2010).
We learned from Part 1 that we needed a better way to estimate the true overall or average treatment effect (ATE). To do this, we ran a smaller (n = 9600) randomized controlled trial (RCT) with the same statistical power and evidence requirements as our RWE explanatory model. We randomly assigned the app to 50% of all trial participants. All participants complied with their treatment assignments, and the app had the same ATE on infection risk as in the RWE dataset.
Here in Part 2, we’ll analyze this synthetic RCT dataset with the same three person-level variables as before: infection status, app usage, and race (Black or White only for simplicity). We’ll also see that if race really is the only confounder of app usage on infection risk (i.e., if we’d observed all possible confounders), then we can estimate the ATE using just our RWE dataset. This requires understanding the Law of Total Expectation—a straightforward and intuitive concept we actually use all the time—that we’ll review below.
Part 2 Objective: To correctly estimate the ATE of app usage on infections using only observational RWE data, given that race is the only other factor that influences infection risk (i.e., the only confounder). As before, we’ll specify the ATE as the risk among users minus that among non-users, or risk difference (RD).
What We’ll Learn: How to estimate the ATE by re-weighting our RWE predictions and outcomes using the g-formula (also called standardization) and propensity score weighting, respectively. The g-formula is closely related to the back-door adjustment formula of Pearl (2009).
We will conclude Part 2 with a high-level action plan for reporting ATE estimates using RWE data.
Dataset Characteristics
The experimental (i.e., randomized) RCT data are in the tibble experimental_rct. (Generate this with the R code in the Appendix.)
glimpse(experimental_rct)## Observations: 9,600
## Variables: 3
## $ race <chr> "White", "White", "White", "White", "White", "White", "Whit…
## $ app <chr> "didn't use app", "didn't use app", "didn't use app", "didn…
## $ infection <chr> "0. uninfected", "1. infected", "0. uninfected", "0. uninfe…Each observation (i.e., row) represents a unique individual who was originally susceptible and uninfected. The variables and their unique values are the same as in Part 1:
knitr::kable(apply(experimental_rct, 2, unique))| race | app | infection |
|---|---|---|
| White | didn’t use app | 0. uninfected |
| Black | used app | 1. infected |
Explanatory Modeling
Our RCT dataset has 9600 observations.
Univariate Associations
Correlation Matrix
dummy_rct <- experimental_rct %>%
dplyr::mutate(
race = (race == "White"),
app = (app == "used app"),
infection = (infection == "1. infected")
)knitr::kable(round(cor(dummy_rct), 4))| race | app | infection | |
|---|---|---|---|
| race | 1.0000 | 0.0054 | -0.3156 |
| app | 0.0054 | 1.0000 | -0.0497 |
| infection | -0.3156 | -0.0497 | 1.0000 |
corrplot::corrplot.mixed(cor(dummy_rct))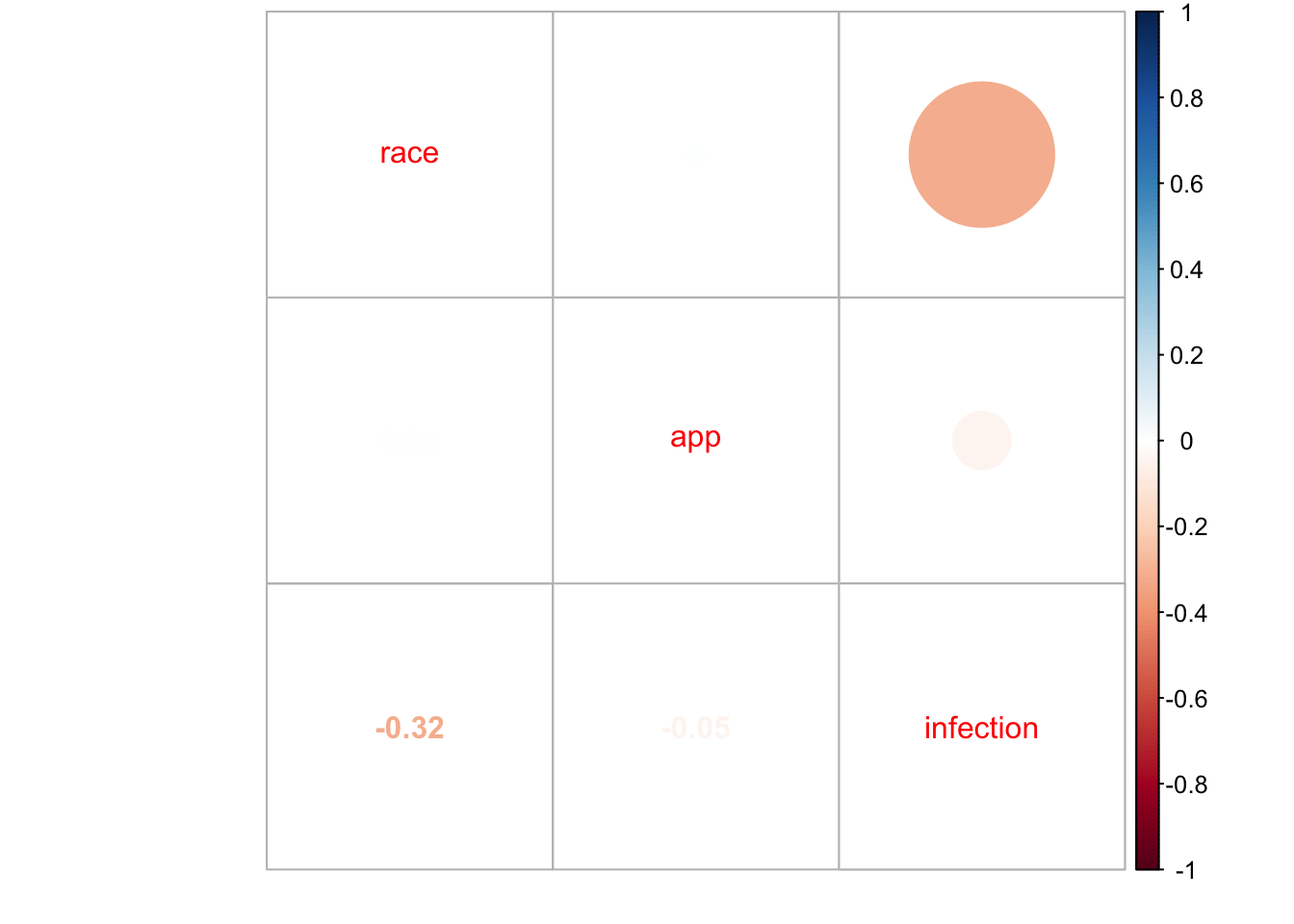
Unlike the RWE correlation matrix in Part 1, race is no longer correlated with app. This is because we randomized app usage.
Infections by App Usage (Marginal Model)
Let’s first examine our main relationship of interest, as we did with the training data.
experimental_rct %>%
ggplot2::ggplot(ggplot2::aes(x = app, fill = infection)) +
ggplot2::theme_classic() +
ggplot2::geom_bar(position = "dodge") +
ggplot2::ggtitle("Infections by App Usage")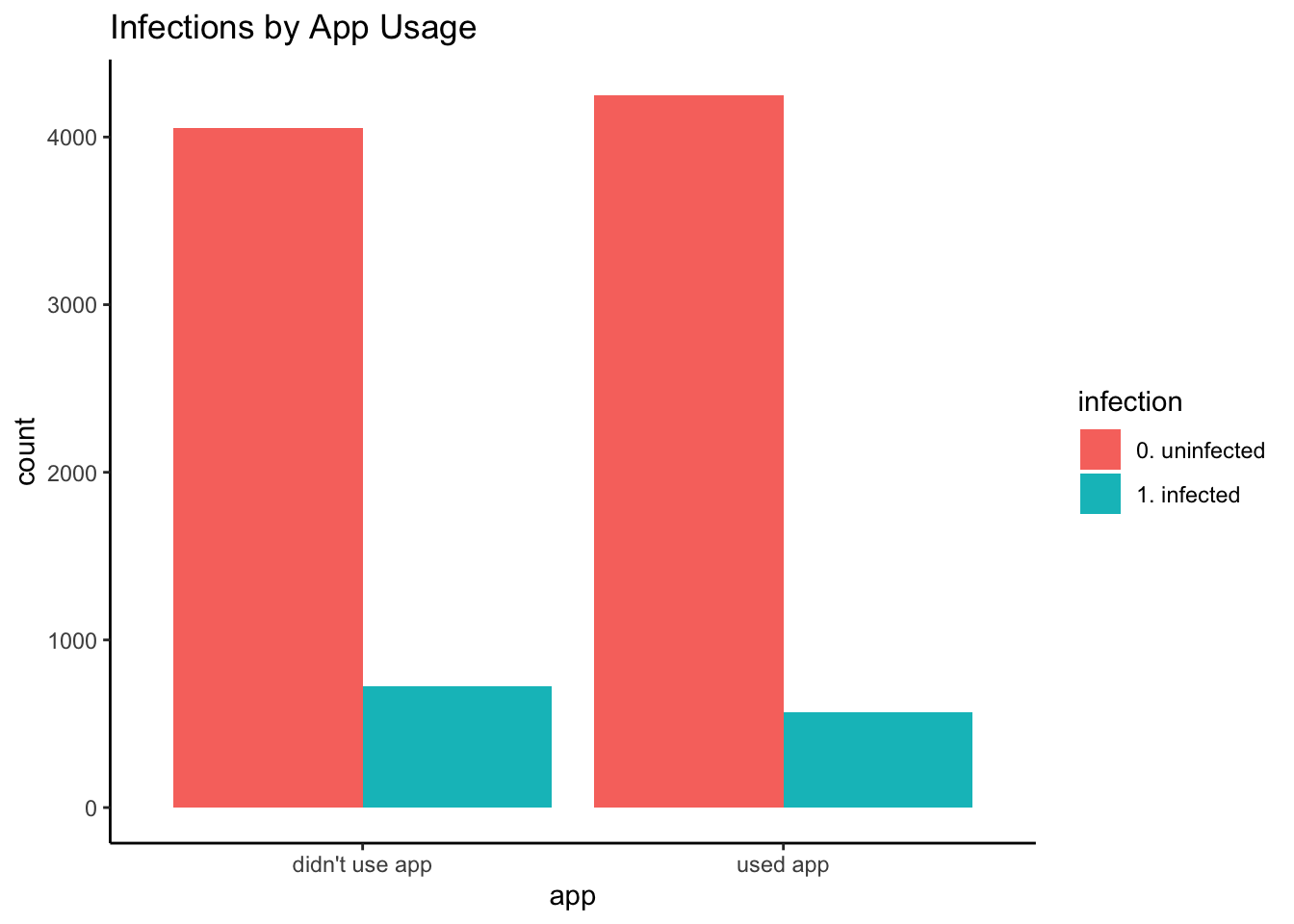
df_rct <- with(
experimental_rct,
cbind(
table(app, infection),
prop.table(table(app, infection), margin = 1) # row proportions
)
)
rct_rd <- df_rct[2,4] - df_rct[1,4]rct_rd # empirical RD## [1] -0.03392808knitr::kable(df_rct) # row proportions| 0. uninfected | 1. infected | 0. uninfected | 1. infected | |
|---|---|---|---|---|
| didn’t use app | 4056 | 726 | 0.8481807 | 0.1518193 |
| used app | 4250 | 568 | 0.8821088 | 0.1178912 |
As in Part 1, there was a lower infection rate among app users: Only 11.8% of users had infections, compared to 15.2% of non-users. However, the empirical RD is -0.034, much closer to the true ATE of -0.031. This is markedly smaller than the “false ATE estimate” of -0.169 (i.e., the RWE holdout empirical RD) that would have misled public health authorities on the true effectiveness of our app at reducing coronavirus infections.
out_fisher_rct <- with(
experimental_rct,
fisher.test(app, infection)
)out_fisher_rct##
## Fisher's Exact Test for Count Data
##
## data: app and infection
## p-value = 1.254e-06
## alternative hypothesis: true odds ratio is not equal to 1
## 95 percent confidence interval:
## 0.6623291 0.8415144
## sample estimates:
## odds ratio
## 0.7466837In addition, there is strong statistical evidence (i.e., statistical significance) that infections varied by app usage (p << 0.001). (Note that this corresponds to a two-sided hypothesis test; our RCT hypothesis is one-sided.) Here, the estimated odds of infection for app users were 0.747 (i.e., roughly three quarters) that of non-users, with a 95% confidence interval (CI) of (0.662, 0.842).
out_epi.2by2 <- epiR::epi.2by2(
with(
experimental_rct,
table(app == "didn't use app", infection == "0. uninfected")
)
)out_epi.2by2$res$ARisk.crude.wald / 100## est lower upper
## 1 -0.03392808 -0.04757939 -0.02027677The corresponding estimated RD with 95% CI is -0.034 (95% CI: -0.048, -0.02). (Note that this corresponds to a two-sided hypothesis test; our RCT hypothesis is one-sided.) That is, we’re 95% confident that using the app lowered the risk of infection by somewhere between 0.02 and 0.048. Note that this is now a statement about a causal effect, not a statistical association.
We could stop here because we designed our RCT in order to properly estimate the ATE. To review from Part 1, the ATE is a marginal quantity in statistical terms because it does not account for (i.e., “is marginalized over”) any other variables. A model that does account for other variables (here, race) in addition to the would-be intervention (here, app usage) is called a conditional model.
But in the Explanatory Model section, we’ll go ahead and fit the Part 1 conditional model that included race as a confounder. In the next section (Causal Inference: It’s the Law), we’ll see how to “roll up” the predictions from this model to equal our estimated RD. We’ll then learn how to use this same procedure to estimate the ATE in a statistically consistent way using our original RWE data.
Infections by Race
As in Part 1, race seems to have been associated with infection.
experimental_rct %>%
ggplot2::ggplot(ggplot2::aes(x = race, fill = infection)) +
ggplot2::theme_classic() +
ggplot2::geom_bar(position = "dodge") +
ggplot2::ggtitle("Infections by Race")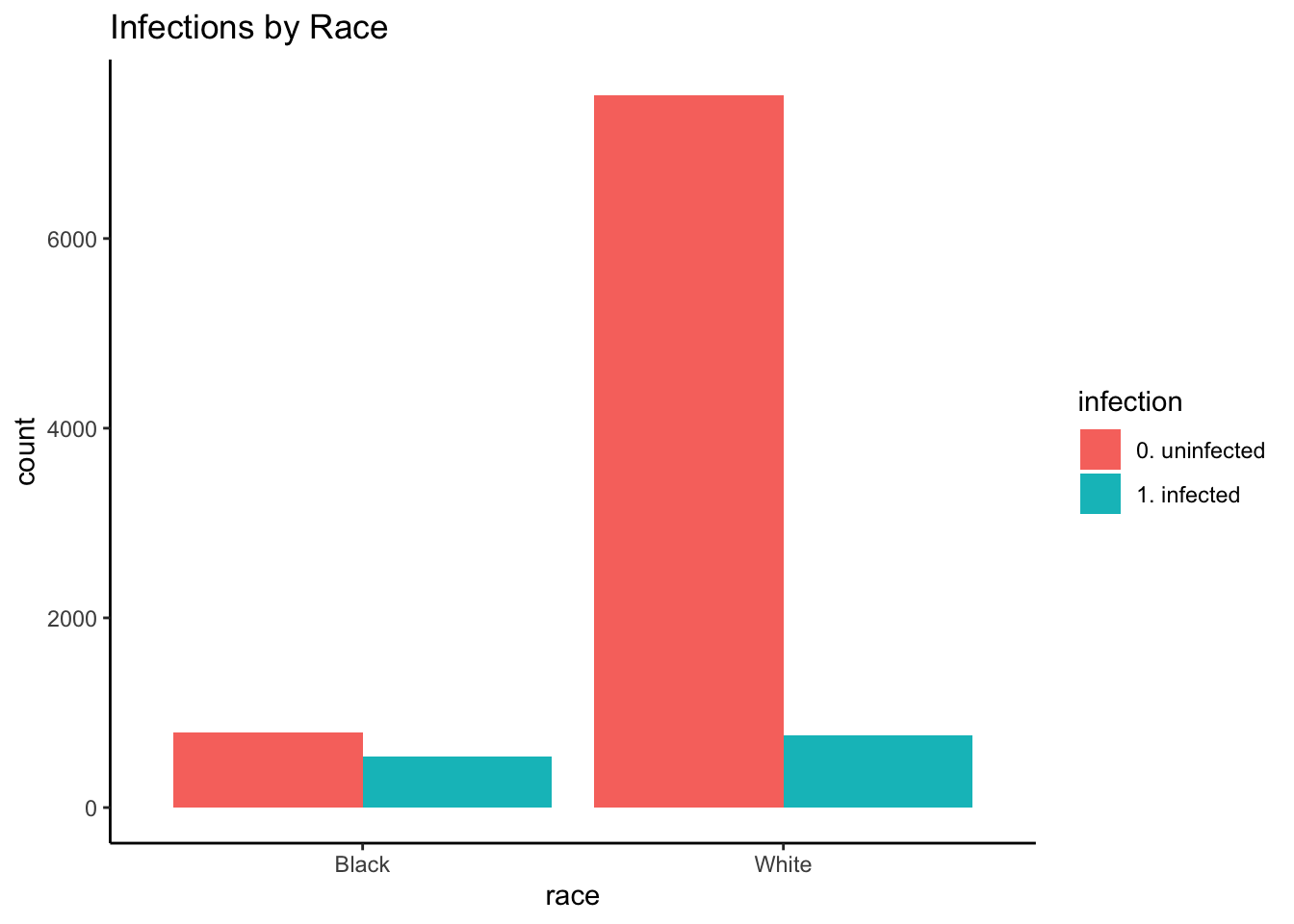
df_rct_race_infection <- with(
experimental_rct,
cbind(
table(race, infection),
prop.table(table(race, infection), margin = 1) # row proportions
)
)knitr::kable(df_rct_race_infection) # row proportions| 0. uninfected | 1. infected | 0. uninfected | 1. infected | |
|---|---|---|---|---|
| Black | 794 | 537 | 0.5965440 | 0.4034560 |
| White | 7512 | 757 | 0.9084533 | 0.0915467 |
out_fisher_rct_race_infection <- with(
experimental_rct,
fisher.test(race, infection)
)out_fisher_rct_race_infection##
## Fisher's Exact Test for Count Data
##
## data: race and infection
## p-value < 2.2e-16
## alternative hypothesis: true odds ratio is not equal to 1
## 95 percent confidence interval:
## 0.1302266 0.1705730
## sample estimates:
## odds ratio
## 0.1490586As before, Blacks were more likely to have been infected than Whites (p << 0.001): 40.3% of Blacks were infected, compared to 9.2% of Whites. Put differently, the estimated odds of infection for Whites were 0.149 (95% CI: 0.13, 0.171) times that of Blacks.
App Usage by Race
Unlike our RWE findings in Part 1, race is no longer correlated with app. Again, this is because we randomized app usage.
experimental_rct %>%
ggplot2::ggplot(ggplot2::aes(x = race, fill = app)) +
ggplot2::theme_classic() +
ggplot2::geom_bar(position = "dodge") +
ggplot2::ggtitle("App Usage by Race")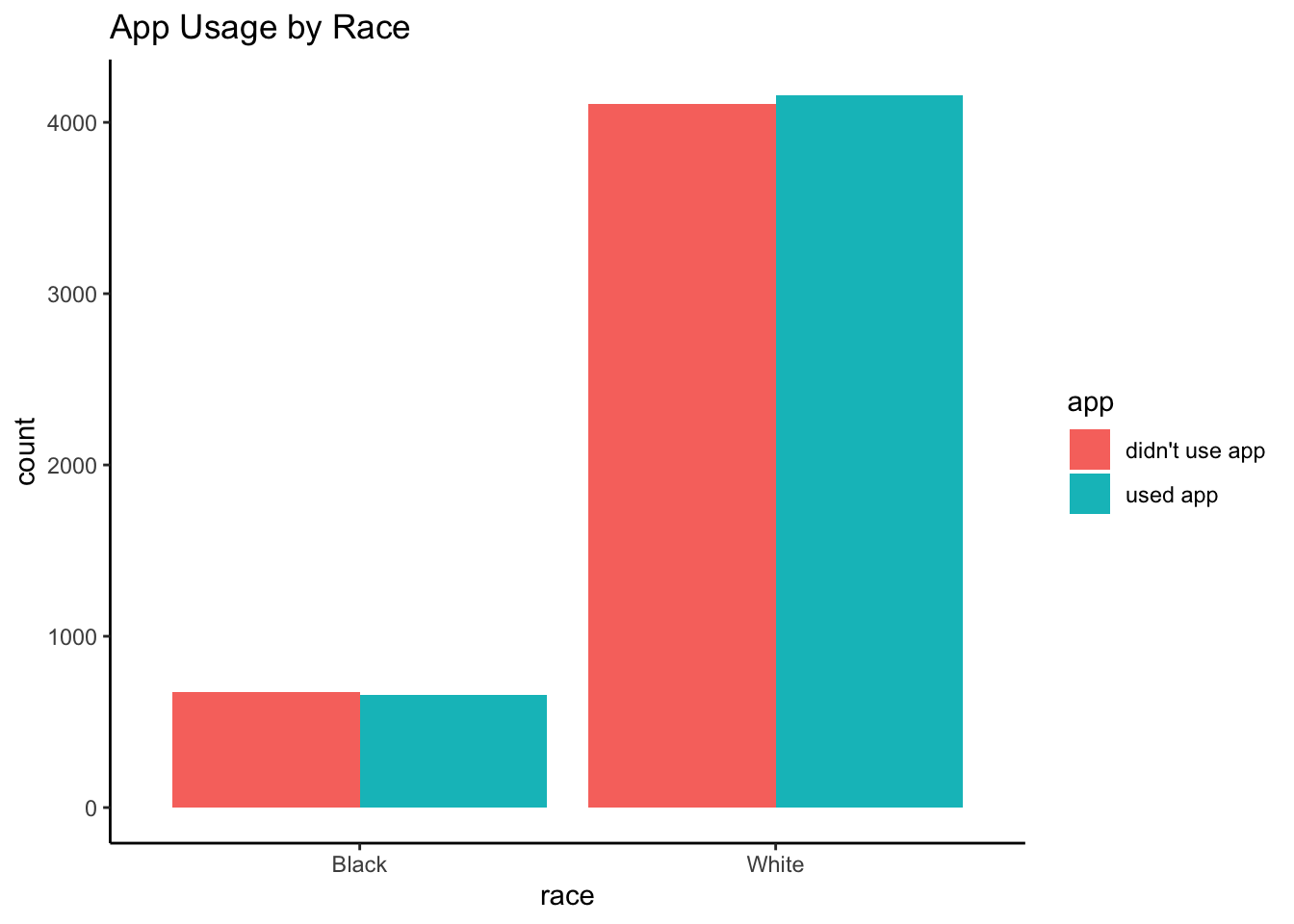
df_rct_race_app <- with(
experimental_rct,
cbind(
table(race, app),
prop.table(table(race, app), margin = 1) # row proportions
)
)knitr::kable(df_rct_race_app) # row proportions| didn’t use app | used app | didn’t use app | used app | |
|---|---|---|---|---|
| Black | 672 | 659 | 0.5048835 | 0.4951165 |
| White | 4110 | 4159 | 0.4970371 | 0.5029629 |
out_fisher_rct_race_app <- with(
experimental_rct,
fisher.test(race, app)
)out_fisher_rct_race_app##
## Fisher's Exact Test for Count Data
##
## data: race and app
## p-value = 0.6156
## alternative hypothesis: true odds ratio is not equal to 1
## 95 percent confidence interval:
## 0.917487 1.160591
## sample estimates:
## odds ratio
## 1.03189Explanatory Model
Causal Model
From Part 1, recall that an explanatory model consists of a causal model and a statistical model. The causal model is often specified as a directed acyclic graph (DAG) (Pearl, 2009). We had assumed that the true DAG was:
- App Usage \(\rightarrow\) Infection
- Race \(\rightarrow\) Infection
- Race \(\rightarrow\) App Usage
DiagrammeR::grViz("
digraph causal {
# Nodes
node [shape = plaintext]
Z [label = 'Race']
X [label = 'App \n Usage']
Y [label = 'Infection']
# Edges
edge [color = black,
arrowhead = vee]
rankdir = LR
X -> Y
Z -> X
Z -> Y
# Graph
graph [overlap = true]
}")Here, race confounds the effect of app usage on infection.
Check Sample Size
Do we have a large enough sample for each app usage and racial group combination to meet our Part 1 statistical power and evidence requirements?
experimental_rct %>%
ggplot2::ggplot(ggplot2::aes(x = race, fill = app)) +
ggplot2::theme_classic() +
ggplot2::geom_bar(position = "dodge") +
ggplot2::ggtitle("App Usage by Race")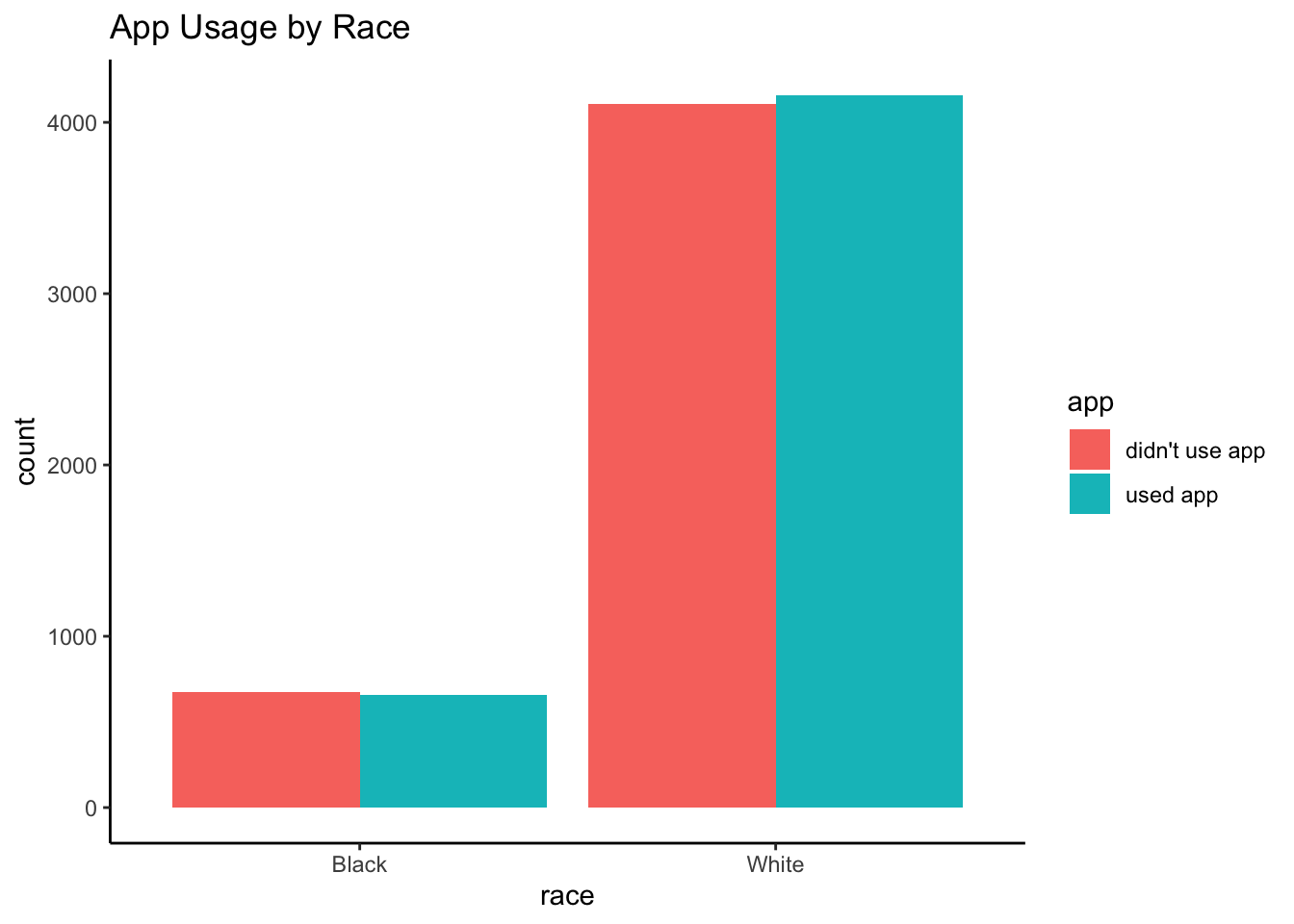
df_rct_race_app <- with(
experimental_rct,
cbind(
table(race, app),
prop.table(table(race, app), margin = 1) # row proportions
)
)knitr::kable(df_rct_race_app) # row proportions| didn’t use app | used app | didn’t use app | used app | |
|---|---|---|---|---|
| Black | 672 | 659 | 0.5048835 | 0.4951165 |
| White | 4110 | 4159 | 0.4970371 | 0.5029629 |
Yes: We have at least 556 Black individuals in each app usage group, and at least 1617 White individuals likewise.
Fit Statistical Model
We fit our RCT logistic model as follows.
glm_rct <- glm(
data = experimental_rct,
formula = as.factor(infection) ~ app + race,
family = "binomial"
)knitr::kable(summary(glm_rct)$coefficients)| Estimate | Std. Error | z value | Pr(>|z|) | |
|---|---|---|---|---|
| (Intercept) | -0.2383012 | 0.0637708 | -3.73684 | 0.0001863 |
| appused app | -0.3133894 | 0.0634329 | -4.94049 | 0.0000008 |
| raceWhite | -1.9089811 | 0.0678516 | -28.13467 | 0.0000000 |
After controlling for race, there is strong statistical evidence (p << 0.001) for the estimated effect of app usage on infection risk. There is also very strong statistical evidence (p <<< 0.001) for race’s association with infection risk. Specifically, the estimated odds of infection for Whites were \(\exp(\)-1.909\() =\) 0.148 (95% CI: 0.13, 0.169) times that of Blacks (regardless of app usage).
The estimated odds of infection for app users were \(\exp(\)-0.313\() =\) 0.731 (95% CI: 0.645, 0.828) times that of non-users (regardless of race). The corresponding estimated infection risks for app usage by race are:
risk_didnt_use_app_black_rct <- plogis(coef(glm_rct) %*% c(1, 0, 0))
risk_used_app_black_rct <- plogis(coef(glm_rct) %*% c(1, 1, 0))
risk_didnt_use_app_white_rct <- plogis(coef(glm_rct) %*% c(1, 0, 1))
risk_used_app_white_rct <- plogis(coef(glm_rct) %*% c(1, 1, 1))- 0.441 for Blacks not using the app
- 0.365 for Blacks using the app
- 0.105 for Whites not using the app
- 0.079 for Whites using the app
The estimated RDs by race are:
rct_rd_black <- risk_used_app_black_rct - risk_didnt_use_app_black_rct
rct_rd_white <- risk_used_app_white_rct - risk_didnt_use_app_white_rct
confint_glm_rct <- confint(glm_rct) # 95% CIs: odds ratios of infection
rct_rd_ci_black <- c(
plogis(confint_glm_rct[, 1] %*% c(1, 1, 0)) - plogis(confint_glm_rct[, 1] %*% c(1, 0, 0)),
plogis(confint_glm_rct[, 2] %*% c(1, 1, 0)) - plogis(confint_glm_rct[, 2] %*% c(1, 0, 0))
)
rct_rd_ci_white <- c(
plogis(confint_glm_rct[, 1] %*% c(1, 1, 1)) - plogis(confint_glm_rct[, 1] %*% c(1, 0, 1)),
plogis(confint_glm_rct[, 2] %*% c(1, 1, 1)) - plogis(confint_glm_rct[, 2] %*% c(1, 0, 1))
)- -0.075 (95% CI: -0.1, -0.047) for Blacks
- -0.026 (95% CI: -0.028, -0.02) for Whites
Causal Inference: It’s the Law
Rolling Up the Conditional Estimated Risks
Randomized Controlled Trial
We can use our explanatory model’s estimated coefficients to predict the infection risk for each person.
experimental_rct_preds <- experimental_rct %>%
dplyr::mutate(predicted_risk = predict(object = glm_rct, type = "response"))
tbl_estimated_risks_rct <- experimental_rct_preds %>%
dplyr::select(race, app, predicted_risk) %>%
dplyr::distinct() %>%
dplyr::arrange(race, app)The predicted risks for each race and app combination are:
knitr::kable(tbl_estimated_risks_rct)| race | app | predicted_risk |
|---|---|---|
| Black | didn’t use app | 0.4407050 |
| Black | used app | 0.3654723 |
| White | didn’t use app | 0.1045855 |
| White | used app | 0.0786616 |
These predicted risks are just the estimated infection risks for app usage by race we’d calculated earlier. (Note that while predicted probabilities such as these are used in classification, they aren’t “predictions” in the classification sense. The latter can only take on the values of “used app” or “didn’t use app”, not continuous probabilities. The predicted risks are “predictions” by the standard statistics—not machine learning—definition.)
We “roll up” these estimated risks to the level of app usage by taking their averages over both racial categories for app users and non-users.
tbl_aac_rct <- experimental_rct_preds %>%
dplyr::group_by(app) %>%
dplyr::summarize(mean_preds = mean(predicted_risk))
estimated_AAC_rct <- tbl_aac_rct$mean_preds[2] - tbl_aac_rct$mean_preds[1]knitr::kable(tbl_aac_rct)| app | mean_preds |
|---|---|
| didn’t use app | 0.1518193 |
| used app | 0.1178912 |
But the estimated RD we calculate from these average estimated risks is exactly the same as the empirical RD we’d calculated earlier!
rct_rd # RCT: empirical RD## [1] -0.03392808estimated_AAC_rct # RCT: RD from average estimated risks## [1] -0.03392808Real-world Evidence
So can’t we just do this with our RWE estimated risks to come up with a similar estimate?
# RWE: empirical RD
df_rwe_holdout <- with(
observational_rwe_holdout, # see Part 1 to generate this:
# https://towardsdatascience.com/coronavirus-telemedicine-and-race-part-1-simulated-real-world-evidence-9971f553194d?source=email-8430d9f1992d-1586971057342-layerCake.autoLayerCakeWriterNotification-------------------------90bb4612_8a36_4b93_81dd_1656d841e715&sk=32bfb03e1ca157e423ecf8cb69835ef3
cbind(
table(app, infection),
prop.table(table(app, infection), margin = 1) # row proportions
)
)
rwe_holdout_rd <- df_rwe_holdout[2,4] - df_rwe_holdout[1,4]
# RWE: RD from average estimated risks
observational_rwe_preds <- observational_rwe_holdout %>%
dplyr::mutate(predicted_risk = predict(object = glm_rwe_holdout, type = "response"))
tbl_estimated_risks_rwe <- observational_rwe_preds %>%
dplyr::select(race, app, predicted_risk) %>%
dplyr::distinct() %>%
dplyr::arrange(race, app)
tbl_aac_rwe <- observational_rwe_preds %>%
dplyr::group_by(app) %>%
dplyr::summarize(mean_preds = mean(predicted_risk))
estimated_AAC_rwe <- tbl_aac_rwe$mean_preds[2] - tbl_aac_rwe$mean_preds[1]knitr::kable(tbl_estimated_risks_rwe)| race | app | predicted_risk |
|---|---|---|
| Black | didn’t use app | 0.4201799 |
| Black | used app | 0.3650084 |
| White | didn’t use app | 0.0947902 |
| White | used app | 0.0766925 |
knitr::kable(tbl_aac_rwe)| app | mean_preds |
|---|---|
| didn’t use app | 0.2598114 |
| used app | 0.0904586 |
rwe_holdout_rd # RWE: empirical RD## [1] -0.1693528estimated_AAC_rwe # RWE: RD from average estimated risks## [1] -0.1693528Apparently not! What happened?
The Law of Total Expectation
Suppose we’ve measured the following heights in feet of two women and six men:
knitr::kable(tbl_lte_example)| id | gender | height |
|---|---|---|
| woman1 | 1 | 4.938729 |
| woman2 | 1 | 5.217788 |
| man1 | 0 | 5.222013 |
| man2 | 0 | 5.820665 |
| man3 | 0 | 5.257096 |
| man4 | 0 | 5.186209 |
| man5 | 0 | 5.788102 |
| man6 | 0 | 5.482407 |
Overall Average
The overall average height is just 5.364. Let \(y_i\) represent the height for individual \(i = 1, ..., n\), where \(n = 8\). This overall average height is explicitly calculated as \(\frac{1}{n} \sum_i^n y_i\), or:
(woman1 + woman2 + man1 + man2 + man3 + man4 + man5 + man6) / 8## [1] 5.364126Overall Average as Weighted Average of Components
But the overall average height is also:
((woman1 + woman2) / 2) * (2/8) + ((man1 + man2 + man3 + man4 + man5 + man6) / 6) * (6/8)## [1] 5.364126Put differently, but using code similar to what we’d used earlier:
tbl_lte_example_components <- tbl_lte_example %>%
dplyr::group_by(gender) %>%
dplyr::summarize(mean_height = mean(height))knitr::kable(tbl_lte_example_components)| gender | mean_height |
|---|---|
| 0 | 5.459415 |
| 1 | 5.078258 |
tbl_lte_example_components[2, 2] * prop.table(table(tbl_lte_example$gender))[2] +
tbl_lte_example_components[1, 2] * prop.table(table(tbl_lte_example$gender))[1]## mean_height
## 1 5.364126Relationship of Overall Average to Component Weighted Average
Let \(z_i = 1\) for women, and \(z_i = 0\) for men. The average height is:
- \(\left( \sum_i^n y_i z_i \right) / \left( \sum_i^n z_i \right) =\) 5.078 for women
- \(\left\{ \sum_i^n y_i (1 - z_i) \right\} / \left\{ \sum_i^n (1 - z_i) \right\} =\) 5.459 for men
The proportion of each gender is:
- \(\frac{1}{n} \sum_i^n z_i =\) 0.25 for women
- \(\frac{1}{n} \sum_i^n (1 - z_i) =\) 0.75 for men
The calculation above adds these two component averages, but it weights each component average by its respective component proportions. Hence, this weighted average is equal to the overall average height:
\[ \left\{ \frac{\sum_i^n y_i z_i}{\sum_i^n z_i} \times \frac{\sum_i^n z_i}{n} \right\} + \left\{ \frac{\sum_i^n y_i (1 - z_i)}{\sum_i^n (1 - z_i)} \times \frac{\sum_i^n (1 - z_i)}{n} \right\} \] \[ = \frac{\sum_i^n y_i z_i}{n} + \frac{\sum_i^n y_i (1 - z_i)}{n} = \frac{1}{n} \left( \sum_i^n y_i z_i + \sum_i^n y_i - y_i z_i \right) \] \[ = \frac{1}{n} \sum_i^n \left( y_i z_i + y_i - y_i z_i \right) = \frac{1}{n} \sum_i^n y_i \]
## [1] "(5.078 * 0.25) + (5.459 * 0.75) = 5.364"## [1] "((woman1 + woman2) / 2) * (2/8) + ((man1 + man2 + man3 + man4 + man5 + man6) / 6) * (6/8) = 5.364"This statement of equivalence is an expression of the Law of Total Expectation (LTE): The overall average is a sum of the component averages weighted by the proportion of each component.
See the Appendix for the definition of the LTE.
Applying the LTE to Our Data
Real-world Evidence: App Users
Let’s now apply the LTE to our RWE holdout data. For simplicity, we’ll just look at app users; similar reasoning holds for app non-users.
- We have \(n =\) 9600 individuals.
- Let \(Y_i = 1\) if individual \(i\) was infected, and \(Y_i = 0\) if uninfected.
- Let \(X_i = 1\) if individual \(i\) used the app, and \(X_i = 0\) if they didn’t.
- Let \(Z_i = 1\) if individual \(i\) is White, and \(Z_i = 0\) if they are Black.
- Let \(\hat{R}_i = \widehat{\text{Pr}} ( Y_i=1 | X_i, Z_i )\) represent the estimated infection risk given \(X_i\) and \(Z_i\).
Among app users, the overall estimated risk was \(\left( \sum_i^n Y_i X_i \right) / \left( \sum_i^n X_i \right) =\) 0.09. The average estimated risk was:
- \(\left( \sum_i^n \hat{R}_i X_i Z_i \right) / \left( \sum_i^n X_i Z_i \right) = \widehat{\text{Pr}} ( Y=1 | X=1, Z=1 ) =\) 0.077 for Whites
- \(\left\{ \sum_i^n \hat{R}_i X_i (1 - Z_i) \right\} / \left\{ \sum_i^n X_i (1 - Z_i) \right\} = \widehat{\text{Pr}} ( Y=1 | X=1, Z=0 ) =\) 0.365 for Blacks
The proportion of each race was:
- \(\left( \sum_i^n X_i Z_i \right) / \left( \sum_i^n X_i \right) =\) 0.952 White
- \(\left\{ \sum_i^n X_i (1 - Z_i) \right\} / \left\{ \sum_i^n X_i \right\} =\) 0.048 Black
The weighted average of average estimated risks taken over both race categories is equal to the overall estimated risk:
\[ \left\{ \frac{\sum_i^n \hat{R}_i X_i Z_i}{\sum_i^n X_i Z_i} \times \frac{\sum_i^n X_i Z_i}{\sum_i^n X_i} \right\} + \left\{ \frac{\sum_i^n \hat{R}_i X_i (1 - Z_i)}{\sum_i^n X_i (1 - Z_i)} \times \frac{\sum_i^n X_i (1 - Z_i)}{\sum_i^n X_i} \right\} \] \[ = \frac{\sum_i^n \hat{R}_i X_i}{\sum_i^n X_i} = \frac{\sum_i^n Y_i X_i}{\sum_i^n X_i} \]
## [1] "(0.077 * 0.952) + (0.365 * 0.048) = 0.09 = 0.09"The last equivalence follows from the definition of a logistic regression. Here’s some code that does this explicitly:
observational_rwe_preds %>%
dplyr::filter(app == "used app") %>%
dplyr::mutate(
weight_Black = (race == "Black") * mean(observational_rwe_holdout$race[observational_rwe_holdout$app == "used app"] == "Black"),
weight_White = (race == "White") * mean(observational_rwe_holdout$race[observational_rwe_holdout$app == "used app"] == "White"),
predicted_risk_weighted = predicted_risk * (race == "Black") * weight_Black +
predicted_risk * (race == "White") * weight_White
) %>%
dplyr::group_by(race) %>%
dplyr::summarize(mean_preds_weighted_rwe = mean(predicted_risk_weighted)) %>%
dplyr::summarize(sum_mean_preds_weighted_rwe = sum(mean_preds_weighted_rwe))## # A tibble: 1 x 1
## sum_mean_preds_weighted_rwe
## <dbl>
## 1 0.0905Compare this to our earlier code we used to calculate the empirical RD, which did not explicitly average of race-specific average estimated risks:
observational_rwe_preds %>%
dplyr::filter(app == "used app") %>%
dplyr::summarize(mean_preds = mean(predicted_risk))## # A tibble: 1 x 1
## mean_preds
## <dbl>
## 1 0.0905Randomized Controlled Trial: App Users
Now let’s apply the LTE to our RCT data. Again, we’ll just look at app users. We’ll use the exact same formulas.
Among app users, the overall estimated risk was 0.118. The average estimated risk was:
- 0.079 for Whites
- 0.365 for Blacks
The proportion of each race was:
- 0.863 White
- 0.137 Black
The weighted average of average estimated risks taken over both race categories is equal to the overall estimated risk:
## [1] "(0.079 * 0.863) + (0.365 * 0.137) = 0.118 = 0.118"Here’s some code that does this explicitly:
experimental_rct_preds %>%
dplyr::filter(app == "used app") %>%
dplyr::mutate(
weight_Black = (race == "Black") * mean(experimental_rct$race[experimental_rct$app == "used app"] == "Black"),
weight_White = (race == "White") * mean(experimental_rct$race[experimental_rct$app == "used app"] == "White"),
predicted_risk_weighted = predicted_risk * (race == "Black") * weight_Black +
predicted_risk * (race == "White") * weight_White
) %>%
dplyr::group_by(race) %>%
dplyr::summarize(mean_preds_weighted_rct = mean(predicted_risk_weighted)) %>%
dplyr::summarize(sum_mean_preds_weighted_rct = sum(mean_preds_weighted_rct))## # A tibble: 1 x 1
## sum_mean_preds_weighted_rct
## <dbl>
## 1 0.118Can you spot the main difference between the four corresponding RWE and RCT components? This difference unlocks the key insight of the g-formula.
The G-Formula
Outcome Model
We had assumed that race and app usage both impact the infection risk. The relevant part of our earlier DAG is:
- App Usage (\(X\)) \(\rightarrow\) Infection (\(Y\))
- Race (\(Z\)) \(\rightarrow\) Infection (\(Y\))
DiagrammeR::grViz("
digraph causal {
# Nodes
node [shape = plaintext]
X [label = 'App \n Usage \n (X)']
Z [label = 'Race \n (Z)']
Y [label = 'Infection \n (Y)']
# Edges
edge [color = black,
arrowhead = vee]
rankdir = LR
X -> Y
Z -> Y
# Graph
graph [overlap = true]
}")Thus far, we’ve been investigating this DAG’s corresponding statistical model. This is often called an outcome model in the causal inference literature because it models how the outcome is statistically related to its input variables (inputs). Our outcome model is a logistic model of infection risk as a function of app usage and race.
G-Formula: Standardizing RWE Estimates
RCT Substitution
In the RWE data, race influenced the propensity of using the app. As a result, app users were more likely to be White than non-users:
knitr::kable(df_rwe_holdout_race_app_colprop) # column proportions| didn’t use app | used app | didn’t use app | used app | |
|---|---|---|---|---|
| Black | 1667 | 607 | 0.5071494 | 0.0477464 |
| White | 1620 | 12106 | 0.4928506 | 0.9522536 |
However, the proportion of each race among app users and non-users were very similar in the RCT data:
knitr::kable(df_rct_race_app_colprop) # column proportions| didn’t use app | used app | didn’t use app | used app | |
|---|---|---|---|---|
| Black | 672 | 659 | 0.140527 | 0.1367787 |
| White | 4110 | 4159 | 0.859473 | 0.8632213 |
This is because randomizing app usage made it statistically independent of race. Hence, the app-usage-specific proportions approximated the overall race proportions, which were:
- \(\frac{1}{n} \sum_i^n (1 - Z_i) =\) 0.139 Black
- \(\frac{1}{n} \sum_i^n Z_i =\) 0.861 White
That is, app users were:
- \(\left( \sum_i^n X_i Z_i \right) / \left( \sum_i^n X_i \right) =\) 0.863 \(\approx\) 0.861 \(= \frac{1}{n} \sum_i^n Z_i\) White
- \(\left\{ \sum_i^n X_i (1 - Z_i) \right\} / \left\{ \sum_i^n X_i \right\} =\) 0.137 \(\approx\) 0.139 \(= \frac{1}{n} \sum_i^n (1 - Z_i)\) Black
So we can set \(X_i=1\) for all \(i\), such that the race proportions we use are:
- \(\left( \sum_i^n 1 Z_i \right) / \left( \sum_i^n 1 \right) = \frac{1}{n} \sum_i^n Z_i =\) 0.861 White
- \(\left\{ \sum_i^n 1 (1 - Z_i) \right\} / \left\{ \sum_i^n 1 \right\} = \frac{1}{n} \sum_i^n (1 - Z_i) =\) 0.139 Black
This is the same as removing [experimental_rct$app == "used app"] from our earlier code like so:
(
experimental_rct_preds %>%
dplyr::filter(app == "used app") %>%
dplyr::mutate(
weight_Black = (race == "Black") * mean(experimental_rct$race == "Black"),
weight_White = (race == "White") * mean(experimental_rct$race == "White"),
predicted_risk_weighted = predicted_risk * (race == "Black") * weight_Black +
predicted_risk * (race == "White") * weight_White
) %>%
dplyr::group_by(race) %>%
dplyr::summarize(mean_preds_weighted_rct = mean(predicted_risk_weighted)) %>%
dplyr::summarize(sum_mean_preds_weighted_rct = sum(mean_preds_weighted_rct))
)$sum_mean_preds_weighted_rct## [1] 0.1184267Statistically, this substitution is acceptable: We are simply replacing one statistically consistent estimate of the true race proportions with another. But what happens if we do this with our RWE data?
RWE Re-weighting
Using our RWE dataset, let’s re-weight the average estimated risks for app users using the overall race proportions instead of the app-usage-specific proportions by removing [observational_rwe_holdout$app == "used app"] from our earlier code like so:
(
observational_rwe_preds %>%
dplyr::filter(app == "used app") %>%
dplyr::mutate(
weight_Black = (race == "Black") * mean(observational_rwe_holdout$race == "Black"),
weight_White = (race == "White") * mean(observational_rwe_holdout$race == "White"),
predicted_risk_weighted = predicted_risk * (race == "Black") * weight_Black +
predicted_risk * (race == "White") * weight_White
) %>%
dplyr::group_by(race) %>%
dplyr::summarize(mean_preds_weighted_rwe = mean(predicted_risk_weighted)) %>%
dplyr::summarize(sum_mean_preds_weighted_rwe = sum(mean_preds_weighted_rwe))
)$sum_mean_preds_weighted_rwe## [1] 0.1176694This quantity is much closer to our RCT estimate. We apply this same re-weighting to the app non-users using the following code:
tbl_ate_gf <- observational_rwe_preds %>%
dplyr::mutate(
predicted_risk = predict(object = glm_rwe_holdout, type = "response"),
predicted_risk_X1 = predict(
object = glm_rwe_holdout,
newdata = observational_rwe_holdout %>%
dplyr::mutate(app = "used app"),
type = "response"
),
predicted_risk_X0 = predict(
object = glm_rwe_holdout,
newdata = observational_rwe_holdout %>%
dplyr::mutate(app = "didn't use app"),
type = "response"
),
gformula_weight = (race == "Black") * mean(observational_rwe_holdout$race == "Black") +
(race == "White") * mean(observational_rwe_holdout$race == "White"),
predicted_risk_weighted = predicted_risk * gformula_weight
) %>%
dplyr::group_by(app, race) %>%
dplyr::summarize(mean_preds_weighted_rwe = mean(predicted_risk_weighted))
estimated_ATE_gf <- (tbl_ate_gf$mean_preds_weighted_rwe[3] + tbl_ate_gf$mean_preds_weighted_rwe[4]) -
(tbl_ate_gf$mean_preds_weighted_rwe[1] + tbl_ate_gf$mean_preds_weighted_rwe[2])We calculate the estimated RD as -0.023. Compare this to our RCT estimated RD of -0.034. Both estimates are much closer to the true ATE of -0.031 than our original RWE estimated RD of -0.169.
The re-weighting procedure can be more generally stated as:
- Calculate the proportion of each combination of confounder values (i.e., the empirical joint distribution of confounders).
- Weight the estimated average outcomes (conditional on all confounders) by their corresponding confounder proportions from Step 1.
- For each would-be intervention group, sum these weighted estimates.
This general procedure is known as the g-formula. The contrast (e.g., difference, ratio) of these standardized sums is a statistically consistent estimate of the ATE.
Intuition: Standardization
Why does this re-weighting method work? The idea is that we can estimate the ATE in a statistically consistent or unbiased way using an RCT. But when we only have RWE data, we can still replicate the way an RCT breaks the influence—and thereby, statistical association—of the confounders on the would-be intervention.
For each would-be intervention group, the g-formula achieves this by standardizing (in epidemiological terms) the distribution of confounders in the RWE to the distribution of confounders in the corresponding RCT. The latter is the same as the overall distribution of confounders (i.e., regardless of intervention group) thanks to randomization.
Propensity Score Weighting
Recall that in our RWE data, Blacks were less likely to have used the app than Whites: Only 27.2% of Blacks used the app, compared to 88.2% of Whites. That is, the propensity to use the app was 0.272 among Black individuals, but 0.882 among White individuals.
observational_rwe_training %>%
ggplot2::ggplot(ggplot2::aes(x = race, fill = app)) +
ggplot2::theme_classic() +
ggplot2::geom_bar(position = "dodge") +
ggplot2::ggtitle("App Usage by Race")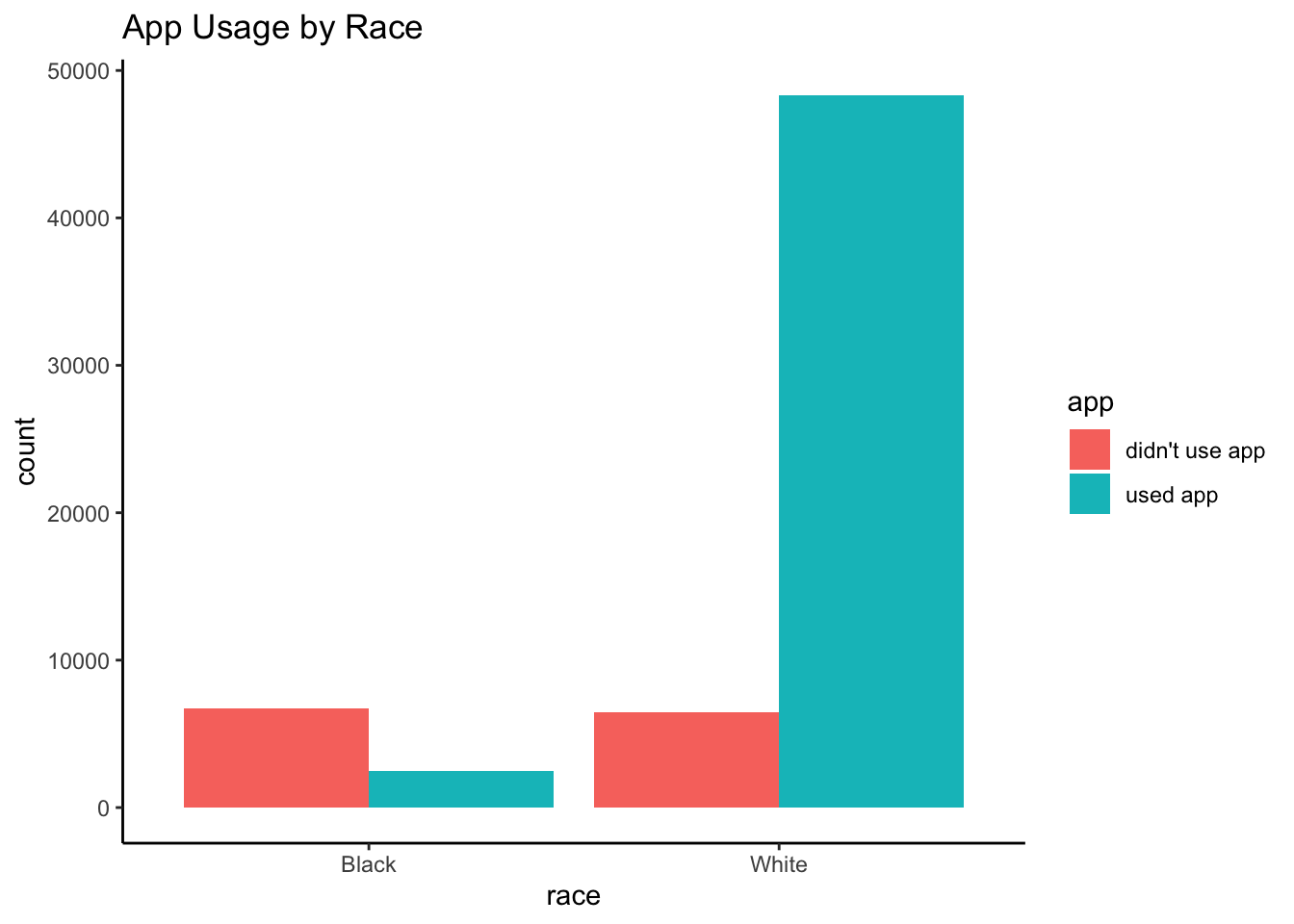
knitr::kable(df_rwe_training_race_app) # row proportions| didn’t use app | used app | didn’t use app | used app | |
|---|---|---|---|---|
| Black | 6698 | 2500 | 0.7282018 | 0.2717982 |
| White | 6474 | 48328 | 0.1181344 | 0.8818656 |
Propensity Model
Causal and Statistical Models
We had assumed that race affects app usage. The relevant part of our earlier DAG is:
- Race (\(Z\)) \(\rightarrow\) App Usage (\(X\))
DiagrammeR::grViz("
digraph causal {
# Nodes
node [shape = plaintext]
Z [label = 'Race \n (Z)']
X [label = 'App \n Usage \n (X)']
# Edges
edge [color = black,
arrowhead = vee]
rankdir = LR
Z -> X
# Graph
graph [overlap = true]
}")Race is said to influence the propensity to use the app. Hence, the statistical model of this relationship is often called a propensity model in the causal inference literature. That is, it models how the would-be intervention is statistically related to its inputs.
The true model for app usage as a function of race is the logistic model listed in the Appendix of Part 1. The propensity to use the app is measured as the probability of using the app. In the context of this causal model, this probability is therefore called a propensity score (Rosenbaum and Rubin, 1983).
In reality, we wouldn’t know this true model. But suppose we’d correctly modeled it and estimated its parameters as follows:
glm_rwe_holdout_ps <- glm(
data = observational_rwe_holdout,
formula = as.factor(app) ~ race,
family = "binomial"
)knitr::kable(summary(glm_rwe_holdout_ps)$coefficients)| Estimate | Std. Error | z value | Pr(>|z|) | |
|---|---|---|---|---|
| (Intercept) | -1.010252 | 0.0474059 | -21.31067 | 0 |
| raceWhite | 3.021527 | 0.0542881 | 55.65728 | 0 |
Now what?
Intuition: Survey Sampling (Horvitz-Thompson Weights)
The propensity to use our app is like a selection process: here, “being selected” to use the app depended on race.
In survey sampling, such selection probabilities are used in probability sampling to ensure that survey participants are representative of the target population from which they are sampled. These probabilities are specified in the survey design—and hence, fully known in advance.
These selection probabilities can then be used to weight the survey respondents’ outcomes by the reciprocal or inverse of their corresponding selection probabilities. This general technique, called inverse probability weighting, provides a statistically consistent estimate of the mean outcome (i.e., the average outcome taken over the entire target population). In survey sampling, the resuling estimator of the population mean is called a Horvitz-Thompson (HT) estimator (Horvitz and Thompson, 1952).
Intuitively, each respondent is weighted in order to represent individuals who are similar in the factors that determine their selection probability. To see how, let’s revisit our earlier example of height and gender:
knitr::kable(tbl_lte_example)| id | gender | height |
|---|---|---|
| woman1 | 1 | 4.938729 |
| woman2 | 1 | 5.217788 |
| man1 | 0 | 5.222013 |
| man2 | 0 | 5.820665 |
| man3 | 0 | 5.257096 |
| man4 | 0 | 5.186209 |
| man5 | 0 | 5.788102 |
| man6 | 0 | 5.482407 |
Suppose these eight individuals were part of a small probability sample (n = 514) taken from a much larger target population (n = 10000). The code to generate the target population and sample is:
# generate target population
mean_height_women <- 5.21654 # from https://ourworldindata.org/human-height
mean_height_men <- 5.61024 # from https://ourworldindata.org/human-height
n_pop_htw_example <- 10000
sel_prob_women <- 0.01
sel_prob_men <- 0.09
set.seed(2004201426)
tbl_htw_example <- dplyr::tibble(
gender = rbinom(n = n_pop_htw_example, size = 1, prob = 0.5),
height = gender * rnorm(n = n_pop_htw_example, mean = mean_height_women, sd = 0.3) +
(1 - gender) * rnorm(n = n_pop_htw_example, mean = mean_height_men, sd = 0.3),
selected = gender * rbinom(n = n_pop_htw_example, size = 1, prob = sel_prob_women) +
(1 - gender) * rbinom(n = n_pop_htw_example, size = 1, prob = sel_prob_men)
)
# select sample
tbl_htw_example_sample <- tbl_htw_example %>%
dplyr::filter(selected == 1)In the target population (with numbers derived from ourworldindata.org/human-height):
- The mean height among women is 5.217 feet.
- The mean height among men is 5.61 feet.
- Women and men are distributed fairly equally: 51% are women.
- The true population mean height is 5.406.
Women were selected into our sample with probability 0.01, and men with probability 0.09. That is, men were nine times more likely to be selected into the sample than women; 90% of our sample are men (n = 464). Hence, the sample overall average height of 5.555 is higher than the true population mean height of 5.406.
However, if we weight each individual by the inverse of their respective selection probability, sum these values, and divide by the total population size, we get the weighted average:
with(
tbl_htw_example_sample,
sum(
c(
height[gender == 1] / sel_prob_women,
height[gender == 0] / sel_prob_men
)
)/nrow(tbl_htw_example)
)## [1] 5.498455This is closer to the true population mean height of 5.406.
Propensity Scores: Weighting RWE Outcomes
We can apply such an HT estimator to estimate the ATE. In our case, there are two types of “target populations” just within our RWE data:
- the population of potential outcomes if every individual had used the app
- the population of potential outcomes if every individual had not used the app
Each potential outcome (Neyman, 1923; Rubin, 1974; Holland, 1986) is observed according to an individual’s actual app usage. The other unobserved potential outcome is called a counterfactual outcome, or simply counterfactual.
We weight each individual by the inverse of their respective propensity score, sum these values, and divide by the total number of individuals in our dataset to get the weighted averages per app usage group:
tbl_ate_ps <- observational_rwe_holdout %>%
dplyr::mutate(
infection01 = (infection == "1. infected"),
app01 = (app == "used app"),
propensityscore_used_app = predict(object = glm_rwe_holdout_ps, type = "response"),
propensityscore_didnt_use_app = 1 - propensityscore_used_app
)
estimated_risk_used_app <- with(
tbl_ate_ps,
sum(infection01[app01 == 1] / propensityscore_used_app[app01 == 1]) / nrow(tbl_ate_ps)
)
estimated_risk_didnt_use_app <- with(
tbl_ate_ps,
sum(infection01[app01 == 0] / propensityscore_didnt_use_app[app01 == 0]) / nrow(tbl_ate_ps)
)
estimated_ATE_ps <- estimated_risk_used_app - estimated_risk_didnt_use_appWe calculate the estimated RD as -0.022. Compare this to our RCT estimated RD of -0.034. Both estimates are much closer to the true ATE of -0.031 than our original RWE estimated RD of -0.169.
Conclusion and Public Health Implications
No Free Lunch
We’ve successfully applied two causal inference methods to estimate the true ATE of app usage on infection risk. These methods are statistically consistent for the ATE, but they rely on some key assumptions being true:
- No Unmeasured Confounders: We’ve observed all possible confounders.
- Correct Model Specification: We’ve correctly specified both the causal and statistical models. (See Part 1 for the difference and relationship between the two.) That is, they both correctly formalize what happens in reality. This assumption applies to the outcome model when using the g-formula, and the propensity model when using propensity score weighting.
- Positivity: There is at least one individual in each intervention group for every unique combination of all observed confounder values (or at least for every rough but reasonably sized unique cluster of said values).
You can learn more about these and other important assumptions in Hernán and Robins (2006) and Hernán and Robins (2020), and at Adam Kelleher’s Medium page.
What’s stopping us from treating as many variables as possible as potential confounders (perhaps after cross-validated model and variable selection)? Why shouldn’t we include them all in the statistical model? One interesting caution against this is the prospect of “M-bias” (Ding and Miratrix, 2015). This is a special type of collider bias (Pearl, 2009) arising from including a model input that is not a confounder. The argument is that including such non-confounders can bias the ATE estimate, due to the induced collider bias.
Choices, Choices
We’ve decided on an RWE explanatory model. But which statistical model should we fit? The outcome model, or the propensity model? Our choice will depend, in part, on how confident we are in fitting either model. And this choice will determine whether we use the g-formula or propensity score weighting.
What if there is only equivocal evidence in favor of one over the other? Perhaps we’re otherwise agnostic to which model to fit. In such cases, there are what are called “doubly robust” estimators that make use of both models (Bang and Robins, 2005). They are called as much because only one of the models needs to be correctly specified in order for the estimator to yield statistically consistent estimates of the ATE.
Other Methods
There are at least three other popular methods for enabling ATE estimation and inference using RWE data.
Matching: In this approach, each individual in one intervention group is matched with at least one other individual in the other intervention group. A match is specified as some level of similarity between both individuals’ observed values for confounders. The idea is that any variation left must be due to the would-be intervention—and is therefore a likely treatment effect.
Propensity Score Matching: What if there are too many confounders over which to find good matches? One well-supported solution is to match individuals in opposite intervention groups using their propensity scores, instead (Hirano and Imbens, 2001; Lunceford and Davidian M, 2004).
Instrumental Variables: The g-formula and propensity score weighting both require that we’ve measured all confounders, and have included them in our statistical model. What if this isn’t possible? Suppose we’ve nonetheless observed another RWE variable that effectively randomized the would-be intervention, was not affected by any confounders, and otherwise had no effect on our outcome. This variable is an instrument we can use to calculate a statistically consistent estimate of the ATE (Angrist and Imbens, 1995).
Public Health Implications
Suppose we mistake [the real-world evidence] empirical RD as an estimate of the ATE. Unbeknownst to us, in our simulated world we would overstate our telemedicine app’s effectiveness by claiming it reduces the risk of new coronavirus infections by 16.9%—when in fact it will only reduce this risk by 3.1%.
But we can re-weight our real-world evidence results to provide more accurate risk-reduction estimates of either 2.3% or 2.2%.
We conclude Part 2 with the following high-level action plan:
- Report and interpret your DAG for your client, along with your unadjusted ATE estimate.
- Adjust for confounding (e.g., through re-weighting). Report and interpret your adjusted ATE estimate to your client.
References
Angrist JD, Imbens GW. Identification and estimation of local average treatment effects. National Bureau of Economic Research; 1995 Feb 1. https://www.nber.org/papers/t0118
Aubrey A. CDC Hospital Data Point To Racial Disparity In COVID-19 Cases. NPR. April 8, 2020 2:43 PM ET. npr.org/sections/coronavirus-live-updates/2020/04/08/830030932/cdc-hospital-data-point-to-racial-disparity-in-covid-19-cases
Bang H, Robins JM. Doubly robust estimation in missing data and causal inference models. Biometrics. 2005 Dec;61(4):962-73.https://onlinelibrary.wiley.com/doi/full/10.1111/j.1541-0420.2005.00377.x
Ding P, Miratrix LW. To adjust or not to adjust? Sensitivity analysis of M-bias and butterfly-bias. Journal of Causal Inference. 2015 Mar 1;3(1):41-57. https://www.degruyter.com/view/journals/jci/3/1/article-p41.xml
Garg S. Hospitalization Rates and Characteristics of Patients Hospitalized with Laboratory-Confirmed Coronavirus Disease 2019—COVID-NET, 14 States, March 1–30, 2020. MMWR. Morbidity and Mortality Weekly Report. 2020;69. cdc.gov/mmwr/volumes/69/wr/mm6915e3.htm
Hernán MA, Robins JM. Estimating causal effects from epidemiological data. Journal of Epidemiology & Community Health. 2006 Jul 1;60(7):578-86. jech.bmj.com/content/60/7/578.short
Hernán MA, Robins JM (2020). Causal Inference: What If. Boca Raton: Chapman & Hall/CRC. https://www.hsph.harvard.edu/miguel-hernan/causal-inference-book/
Hirano K, Imbens GW. Estimation of causal effects using propensity score weighting: An application to data on right heart catheterization. Health Services and Outcomes research methodology. 2001 Dec 1;2(3-4):259-78. https://link.springer.com/article/10.1023/A:1020371312283
Holland PW. Statistics and causal inference. Journal of the American statistical Association. 1986 Dec 1;81(396):945-60. https://www.jstor.org/stable/pdf/2289064.pdf
Horvitz DG, Thompson DJ. A generalization of sampling without replacement from a finite universe. Journal of the American statistical Association. 1952 Dec 1;47(260):663-85. https://www.jstor.org/stable/pdf/2280784.pdf
Lunceford JK, Davidian M. Stratification and weighting via the propensity score in estimation of causal treatment effects: a comparative study. Statistics in medicine. 2004 Oct 15;23(19):2937-60. https://onlinelibrary.wiley.com/doi/abs/10.1002/sim.1903
Neyman J. On the application of probability theory to agricultural experiments. Essay on principles. Section 9. Statistical Science. 1923, tr 1990;5(4):465-480. Translated and edited by D.M. Dabrowska and T.P. Speed from the Polish original, which appeared in Roczniki Nauk Rolniczych Tom X (1923) 1-51 (Annals of Agricultural Sciences). https://www.jstor.org/stable/pdf/2245382.pdf
Pearl J. Causality. Cambridge university press; 2009 Sep 14. bayes.cs.ucla.edu/BOOK-2K/
Robins J. A new approach to causal inference in mortality studies with a sustained exposure period—application to control of the healthy worker survivor effect. Mathematical modelling. 1986 Jan 1;7(9-12):1393-512. sciencedirect.com/science/article/pii/0270025586900886
Rosenbaum PR, Rubin DB. The central role of the propensity score in observational studies for causal effects. Biometrika. 1983 Apr 1;70(1):41-55. academic.oup.com/biomet/article/70/1/41/240879
Rubin DB. Estimating causal effects of treatments in randomized and nonrandomized studies. Journal of educational Psychology. 1974 Oct;66(5):688. https://psycnet.apa.org/fulltext/1975-06502-001.pdf
Shmueli G. To explain or to predict?. Statistical science. 2010;25(3):289-310. projecteuclid.org/euclid.ss/1294167961
Appendix
The Law of Total Expectation (Continued)
The more general (abstract) expression of the statement from our earlier height-by-gender example is
\[ E (Y|Z=1) \times \Pr (Z=1) + E (Y|Z=0) \times \Pr (Z=0) = E (Y), \]
where \(E ( \cdot )\) is the expectation operator. Note that the variables are now all upper-case, indicating that they are random variables (e.g., due to random sampling)—unlike the lower-case fixed variables in our height-by-gender example.
The expectation operator takes the expectation (i.e., expected value or mean) of the random variable inside the parentheses like so:
- It multiplies each possible value with its corresponding probability.
- It then sums over all of these.
Loosely speaking, the expectation operator calculates a weighted average—with probabilities as the weights.
The expression \(E(Y|Z)\) denotes a conditional expectation, where the expectation of \(Y\) is taken over all \(Y\) at a given value \(Z\). The general expression above can be compactly stated as
\[ E (Y|Z=1) \times \Pr (Z=1) + E (Y|Z=0) \times \Pr (Z=0) = E_Z \left\{ E ( Y | Z ) \right\} , \] where \(E_Z ( \cdot )\) specifies taking the expectation of the expression inside the parentheses over all values of \(Z\).
The Law of Total Expectation states:
\[ E(Y) = E_Z \left\{ E ( Y | Z ) \right\} \] That is, the expected value of a random variable \(Y\) is equal to expectation of the expected value of \(Y\) conditional on a different random variable \(Z\), taken over all values of \(Z\).
RCT Simulation R Code
##### Set simulation parameters
### Preliminaries
random_seed <- 2004101447
sample_size_observational <- 80000
holdout_proportion <- 0.2
sample_size_experimental <- sample_size_observational * holdout_proportion * 0.6
### Feature distribution
piZ <- 0.755 / (0.755 + 0.127) # race (based on U.S. Census)
### Outcome model
# beta0 and betaZ are derived from:
# https://www.cdc.gov/mmwr/volumes/69/wr/mm6915e3.htm
# https://www.npr.org/sections/coronavirus-live-updates/2020/04/08/830030932/cdc-hospital-data-point-to-racial-disparity-in-covid-19-cases
# https://www.washingtonpost.com/news/powerpost/paloma/the-health-202/2020/04/09/the-health-202-los-angeles-is-racing-to-discover-the-true-coronavirus-infection-rate/5e8de70588e0fa101a75e13d/
prInfection <- 0.15
prBlack <- 1 - piZ
prWhite <- piZ
prBlackGivenInfection <- 33 / (33 + 45)
prWhiteGivenInfection <- 1 - prBlackGivenInfection
prInfectionGivenBlack <- prBlackGivenInfection * prInfection / prBlack
prInfectionGivenWhite <- prWhiteGivenInfection * prInfection / prWhite
beta0 <- log(prInfectionGivenBlack / (1 - prInfectionGivenBlack)) # baseline: infection risk for Blacks who don't use app
betaX <- -0.3
betaZ <- log(prInfectionGivenWhite / (1 - prInfectionGivenWhite)) - beta0 # average influence of being White on infection risk
### Propensity model: app usage
alpha0_experimental <- 0 # randomized controlled trial: 0.5 randomization probability
alphaZ_experimental <- 0 # randomized controlled trial: 0.5 randomization probability
##### Generate data.
set.seed(random_seed + 3)
experimental_rct <- dplyr::tibble(
race = rbinom(n = sample_size_experimental, size = 1, prob = piZ),
app = rbinom(n = sample_size_experimental, size = 1, prob = plogis(alpha0_experimental + alphaZ_experimental * race)),
infection = rbinom(n = sample_size_experimental, size = 1, prob = plogis(beta0 + betaX * app + betaZ * race))
) %>%
dplyr::mutate(
race = ifelse(race == 1, "White", ifelse(race == 0, "Black", NA)),
app = ifelse(app == 1, "used app", ifelse(app == 0, "didn't use app", NA)),
infection = ifelse(infection == 1, "1. infected", ifelse(infection == 0, "0. uninfected", NA))
)